From Privacy to Penalties: Is Google giving users what they asked for?

Google is the Internet's undisputed number one destination. It is the hub where most Internet usage begins, and many users couldn't imagine navigating the vast information highway without consulting Google's notoriously simple interface. However, as widely used as it is, Google is also a controversial company that has often found itself at the heart of public dispute, most recently with the E.U parliament's decision to break up Google.
This article will attempt to shine a light on Google's practices which, on more than once occasion, abused its position in the industry to further ends that were either immoral, counter-productive to its users, or both. Among these practices are penalties, marginalization of organic search results, and finally, repeated strikes and violations when it comes to user privacy.
Google's corporate motto used to be "Don't be Evil"; looking at some of the measures taken by the giant search in recent years, as well as its standing policies, it's pretty easy to see why they decided to drop it. Through an overall examination of Google's history, steps and practices, it'll be argued that Google contradicts its declared objectives of improving user experience and fair competition. The first issue under the microscope is a sore spot for many website owners: penalties.
Penalties
Today, searches on Google are easier than ever before, thanks to filters that make it simple to sift through results. These filters, such as images, video, news, shopping and more, improve the user experience. However, have these changes actually improved search results? In order to answer this question, it's first necessary to define what 'improvement' means, and to whom.
Some three years have passed since the online world witnessed a revolution, with the increased use of various manual and algorithmic search engine penalties. Penalties like Panda and Penguin affected millions of websites, resulting in lowered rankings. Many have yet to bounce back, many were deserted or removed, all in the name of the war against spam.
According to Matt Cutts, an estimated 400,000 websites receive manual penalties every month. Algorithmic penalties, though not officially confirmed, are likely used dealt out in a similar frequency. Unlike algorithmic penalties, manual penalties can only be removed by directly communicating with Google's spam team via a request for website reconsideration. Spam isn't the way to go, and there's great value in improving search engine results; however, there is fault in the way that Google, being a large, reputable corporation, handles these penalties and their removal process.
Anyone who's ever submitted a reconsideration request when attempting to lift a manual penalty, has a good chance of encountering Google's laconic, semi-canned responses, which can even be perceived as hurtful to a site owner who's likely taken a severe financial hit as a result of the penalty. Google often lists incomplete, confusing or contradictory explanations that can hurt the site's chances of recovering, as found in this example.
It would be far more beneficial to everyone if Google were more specific in their replies.
There are numerous opinions citing countless reasons defending Google's behavior, including manpower, accountability limitations and the right to protect the secrecy of their own intellectual property. As mentioned before, spam is an unfavorable practice, but there are real people behind every business. To paraphrase a well-known film, with Google's great power comes great responsibility: all businesses have limited resources, but when the lifeline of many businesses is their online users - the responsibility falls on Google to provide effective, targeted support.
Unfortunately, the vast majority of site owners who find themselves penalized don't even know the reason, and more often than not they have been led to execute bad practices by inexperienced professionals, or worse, outright spammers.
Moving from lacking support to an even earlier flaw in the penalty process, let's discuss the fact that Google penalizes sites for breaking its rules - even if said breech happened before these rules were made public. The simplest analogy to illustrate why this is problematic is borrowed from legislature: legal obligations and rights are not enforced retroactively, rather from the time the law was enacted, moving forward. It's important to keep in mind that most violations that Google views so severely, which ultimately lead to penalties, often weren't violations to begin with. Yet, Google penalizes websites regardless of its guidelines at the time of the so-called violation.
Let's take the Penguin algorithm update, for instance. Penguin is an algorithm that devalues websites for having unnatural link profiles. As most may know, Google's guidelines are updated every few months, and many website owners find themselves penalized for bad links they assembled years ago - when such methods weren't explicitly prohibited (questionable, yes - but not prohibited).
Moreover, many methods were considered 100 percent acceptable at the time they were used, but due to abuse they ceased being effective, and later started to damage rankings (article directories are an example of such a shift, for those who still remember).
Some argue that if Google hadn't taken action, search results would have become no more than a scrambled list of URLs it's difficult to make sense of. Well, they did take action, raging a war against spam in which many think they went too far, essentially throwing out the baby with the bath water.
Google's new approach is to trust authority, and show results if and when they're also relevant to a search query. In reality, big ('trusted') corporations are being favored, while small businesses are pushed down, causing lost revenue. What went wrong along the way?
Guest posts are a great example of this unevenness. This method worked seamlessly up until about a year ago, when it was adopted by spammers and companies out for a quick buck. The Web was inundated with emails offering low-cost guest posts:
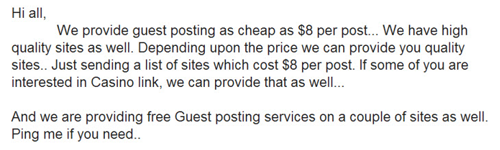
Anyone dealing with content is surely aware that no quality guest post, which requires hours of writing and distribution, can cost only $8. Even 10 times that sum is a stretch. Google quickly realized the Internet was harboring spam content, and updated their guidelines accordingly to exclude excessive guest posts.
Obviously, these guidelines only affected websites linked to from a certain (low) quality of posts, but still, numerous websites were affected by this rule despite not knowing it was prohibited to begin with. It's like parking your car in front of your house for the past 10 years, and then learning that the municipality decided it's a no-parking zone, promptly hitting you with a decade's worth of back-dated parking tickets.
I'd expect a bit more reason from a global leader such as Google. Specifically, I'd expect Google to penalize websites for utilizing practices only after these are declared prohibited.
Why? What? How?
If Google can't be fair in dealing its penalties, it's reasonable to expect fairness when attempting to remove them. No such luck. Unlike manual penalties, whereby site managers see a notification in WMT, Penguin and other algorithms leave site owners with no indication or alert to the fact the site's been devaluated. Again, the secrecy is legitimate, but if someone does something wrong, they have the right to know about it and not be obscurely punished, leaving their business to slowly die.
Such instances can cause site owners great distress and helplessness. They may not be constantly aware of the site's performance, and may only realize they've been given a penalty after experiencing its financial implications. Why not notify site owners of algorithmic penalties?
Google does not provide any information to site owners affected by an algorithm, especially not how to get out of an algorithmic penalty. Site owners have no number to call, no email to write to and no live-chat to engage with to get answers. Think about it: a company worth billions, and catering to billions, has no customer service to speak of. In this reality, Web marketers who published blogs, posts, and lengthy tutorials on the subject, effectively serve as Google's (free) customer service. The thorough case studies, guides and troubleshooting that can be found on the Web were written by Web marketers, and not endorsed or recognized officially by Google.
Pretty sweet deal for the search giant, right?
True, Google has a forum where everyone can upload questions, but even there - it's not Google's own employees who respond with advice on a specific question. It's also hard to believe that Google has no way of knowing precisely why a site's dropped in rankings (that's a popular claim, too) when there's an algorithmic penalty involved. Surely, there's a way to generate a report whenever a website is recognized as breaking Google's guidelines.
However it's examined, Google's users and the site owners have every right to complain about faulty user experience. Before chiming in and claiming site owners' complaints shouldn't be taken into Google's consideration, it's important to keep in mind that without site owners, Google wouldn't be able to occupy such a large market share, nor earn nearly as much as it does from PPC.
Suffering the Consequences of Penalties: The Micro Level
In addition to the financial hit most site owners suffer following a penalty, it's important to clarify that these penalties' effect goes far beyond one particular website's struggle to return to high rankings in search results. In this day and age of globalization and digitization, many businesses exist mainly (and even solely) through providing online services. Such a website may employ, for instance, 1,000 employees, would need to downsize its manpower significantly post-penalty, thus contributing to unemployment and perhaps even poverty.
Several months ago, owner of Mahalo, Jason Calacanis, cited Matt Cutts personally and accused him of being responsible for having to fire 80 employees ("salt of the earth", as the owner put it):

Screenshot was taken from seroundtable.com on 08/15/14
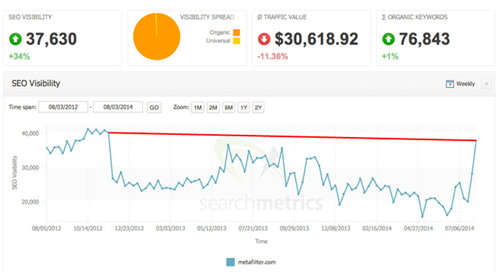
And what about mistakes? Remember the mysterious, uncited penalty that affected MetaFilter? In Nov., 2012, the company's website was hit with a mysterious penalty whose very existence was denied by Google. After 20 long months, their website managed to restore its rankings (according to SearchMetrics), and achieve a 34 percent increase in their visibility. Several months later, Google admitted the site had received a penalty by mistake (!). And they aren't the only site. Now imagine the scope of devastation this company must have suffered after 20 months at unrealistic rankings.
It's important to keep in mind that it's not always wealthy business owners and large corporations affected, who can often minimize the damages or absorb them by investing more in paid advertising. In many case, we're seeing small and medium businesses take a hit, companies whose entire livelihood (or a significant portion of it) depends on the income from their website. In such instances, penalties may mean bankruptcy - plain and simple. Now keep in mind that all this devastation is brought on by practices that are in no way illegal or criminal, simply failure to comply with the guidelines established by a private corporation.
Global Consequences of Penalties: The Macro Level
Up to this point, this article has dealt with the effects of penalties dealt out by Google.com, but it's just as important to stop to think about what goes on in other countries, where Google's local search is most commonly used. Particularly, it's crucial to consider websites that aren't written in English, as Google is far less accurate when scanning them.
Since Google's algorithm can't assess the quality of non-English websites at the same level it does English websites, gaps are created. These gaps are then used by spammers to infiltrate their way to the top of search results. In the U.S., if a large company is penalized, odds are another large company will take its place in search results; when it comes to Google Local (Sweden, Israel, France, etc.), the number of large companies is significantly smaller, therefore, when a large company is penalized, there isn't always another large, reputable company to take its place in search results.
This is a crucial point: going back to the original question (what defines 'improvement' when it comes to search results?), it most certainly has to do with the most relevant result for a given user, and the highest quality result in terms of trustworthiness, user experience, customer service, etc.
If this is what Google wants to deliver to its users, it's missing the mark entirely. Since websites are penalized retroactively, the odds of a long-standing, established website getting a penalty are exponentially greater than those of a new website. User experience is compromised when a small, up-and-coming or recently launched site can replace large, established, and highly frequented site at the top of search results. Of course, the majority of sites, new or old, are trustworthy and out to make an honest living - but one cannot ignore that there are spammers working day and night to launch new sites out of the blue, easily taking over local search results.
Such an instance took place in Israel recently, following both Penguin and Panda updates. Yesplease.co.il is one of the largest leads sites in Israel, operating in the field of business and home professionals (plumbers, lawyers, etc.), and has been active for over a decade. It's a legitimate, reputable company that offers great customer service and support, and has also invested greatly in user experience.
Several months ago, the site received a penalty, and was replaced in search results by a newer, far less established website. The competing website offers no customer service and a significant downgrade when it comes to user interface (in all opinions). Was the user's experience improved in the slightest? Clearly, it was not. The person initiating the search was not referred to the best, most trustworthy, reputable, and relevant result.
Sure, Google can only be held responsible for search results, and they have no way of accurately assessing which company is better when it comes to service or products (at least not at a level which would solve all of their problems). However, the problem of lesser companies ending up at the top of search results has escalated in the past 6 months and it feels like no one at Google seems to mind. In these types of cases, it's crucial that Google realizes it's better to be smart than correct: many choose to adapt and do whatever they think is best for them instead of waiting for Google to do justice, often opting for a different platform to gain visibility.
How Google Took Over Organic Results
Originally, Google was a simple search engine. It was its simplicity, more so than anything else, which helped it gain in popularity. Over the years, it has changed significantly, both visually and technically. If we take a look at search results from the late 90s and compare them to search results today, it's easy to spot countless differences. Nowadays, the top 10 results often can't even be seen on the first page, due to all the images, videos, news items and other elements Google introduced.
My colleague Branko Rihtman wrote a post addressing these changes, and illustrated them perfectly. This is what Google search results pages looked like 10 years ago:
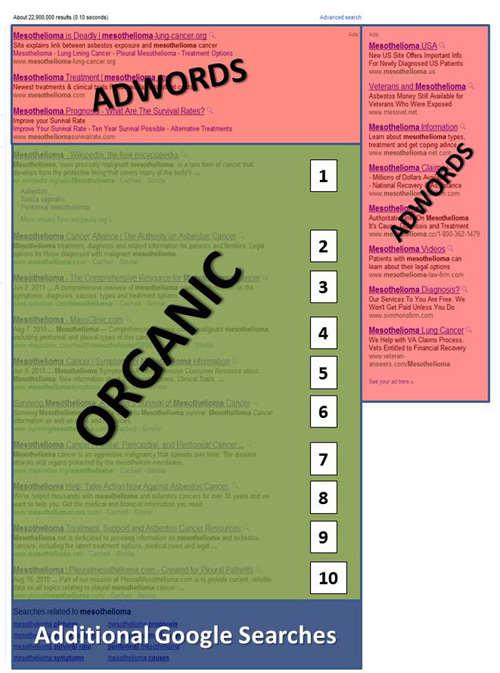
And here's one of the layouts that can be seen nowadays:

The above configuration is still somewhat reasonable; although there are only five regular organic results displayed, local searches do warrant the display of local results. This recent layout was available when Google still stuck to its original purpose, emphasizing the end user's experience, but things took a turn for the worse when Google Shopping (and tourism offers) started to infiltrate results pages.
In 2011, the U.S. Senate held a hearing where CEO of price comparison giant NexTag, Jeffrey Katz, testified:
"But what Google engineering giveth, Google marketing taketh away. Google abandoned these core principles when they started interfering with profits and profit growth. Today, Google doesn't play fair. Google rigs its results, biasing in favor of Google Shopping and against competitors like us. As a result, Nextag's access is more and more discriminated against. Not because our service has gotten worse - in fact, our service is much better than it has ever been - but because we compete with Google where it matters most, for very lucrative shopping users."
Once Google effectively began selling through their website, we started stumbling upon sponsored ads within search results. In the example below, a search for hotels in Las Vegas - note the extent of Google's takeover of organic results, primarily through its sponsored ads that include the display of ratings and pricing, parameters they don't make available to any of their competitors' results:
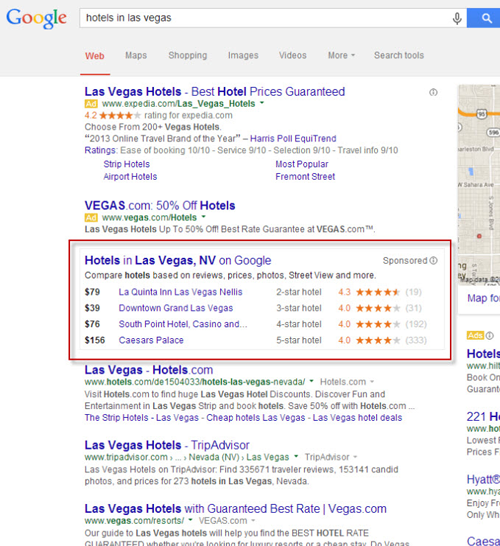
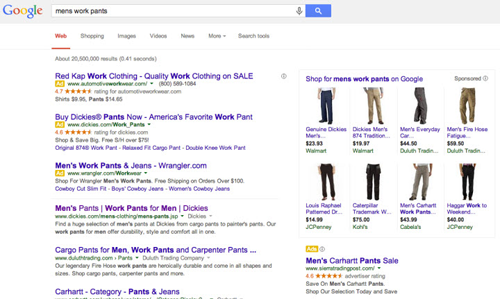
Behind every such change, the first explanation Google provides has to do with the benefit to users. While indeed many of the changes made through the years simplify user experience, Google's continued exploitation of its popularity (and said 'user experience' argument) to benefit its own bottom line is bothersome, especially since it fails to provide businesses a fair chance or equal visibility in organic results. The example above shows unfairness toward huge, profitable hotels in Las Vegas, whom we may not feel sorry for and who may be able to compensate with other forms of visibility, but similar examples can be found in smaller niches. Imagine, for instance, a small town with several inns that aren't given a fair chance to reach potential clients.
Once again, the unfair competition extends further - even to non-profit organizations, such as Wikipedia. Several months ago, Matt Cutts tweeted a link to a new lead form that users can fill out to report scraped content and scraper sites.

This tweet spread like wild fire after it came to light that Google itself was in breach of its guidelines, using scraped content from other websites when it suited it. In an absurdly accurate example, one tweeter pointed out that Google had lifted the very definition of "scraper site" directly from Wikipedia:
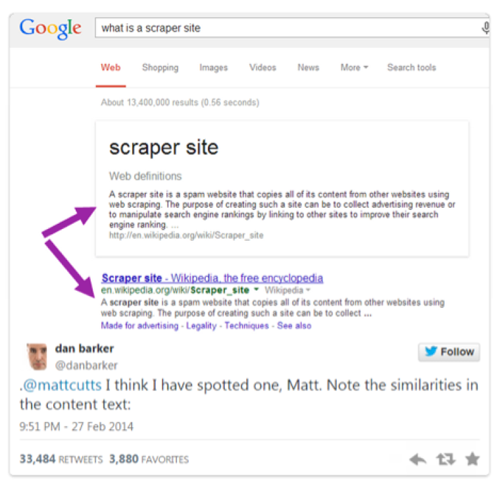
When inputting the search phrase 'what is a scraper site', tweeter Dan Barker saw Google's definition displayed at the top of search results as part of its Knowledge Graph. By displaying this info, directly taken from Wikipedia, Google essentially canceled out all other results. The problem with this is that hardly any user would click through to the URLs in the results after seeing the abridged version of what they searched for right then and there. Google severely damaged Wikipedia's chances of getting traffic, and thus potential support for its free-information manifesto, even though Wikipedia created the content and were the most relevant result - as evidenced by their appearance at the top of organic results.
Users' Fragile Right to Privacy
The grand majority of Google's income originates from advertising, and totals approximately 16 billion USD per quarter, according to the latest report. In order to optimize advertisers' spend, Google uses users' private information, obtained through scanning their Gmail accounts, search history, surfing history and ad clicks. All of this information is stored on Google's services where it's analyzed and helps determine which ads should be displayed. This information also feeds Google Trends, and helps them determine which topics are about to go viral. All in all, it seems this isn't so bad - who wants to see irrelevant ads?
It doesn't stop there. In 2012, the Wall Street Journal exposed that Google had blatantly exploited Safari browser's security settings to stalk the usage habits of iOS and Mac users, even though they had signaled they weren't interested in providing said information. Google systematically collected information about users without their knowledge and without their consent, thanks to a loophole in said security settings. After this came to light, Google was fined 22 million dollars - a ridiculously low, insignificant sum when considering the volume of information they managed to collect and profit from.
Similarly, in early 2013, the New York Times reported on yet another scandal involving Google's disregard for user privacy. After being sued by 38 different countries, Google admitted that while capturing photography for their Street View Tool, the odd vehicle with cameras didn't just record footage of surrounding streets - but also collected 600 GB of data from nearby Wi-Fi networks, including passwords, e-mails and private data. For this, Google was fined 7 million dollars, once again a laughable sum. The list of examples that demonstrate Google's less-than-innocent practices could go on further, but the message is clear.
To anyone who thinks these are isolated incidents or human errors, take a look at this excerpt from an interview Eric Schmidt, Google's CEO, gave the Huffington Post on the subject of user privacy:
"If you have something that you don't want anyone to know, maybe you shouldn't be doing it in the first place."
Confusing. Isn't that the point of having privacy laws (or a personal computer) to begin with? Everyone has things they'd like to keep private, and not share with the entire Internet community. This doesn't necessarily mean it's something embarrassing, it can be as innocent as pictures of loved ones, private letters, documents containing ideas in development that haven't yet been published or patented and many other types of information. Just because something's private, it isn't automatically shameful or guilt-inducing - it just means someone would prefer to keep it to themselves as part of their innate, basic right to privacy.
In light of these repeated breaches, the European Union passed a law, several months ago, that every person has the right to be forgotten. This law enables people whose name yields unfavorable results in Google search, to file a request for Google to remove these results. Naturally, Google didn't look kindly at this attempt to interfere with it practices, and quickly found a loophole. They conceded to the law, and indeed removed any results they were requested to remove. However, when searching for said person's name, in lieu of the removed results, the person searching would see a statement attesting to the result having been removed following a request in compliance with this law. In doing this, Google ensures few people will request to remove unfavorable results about them; after all, what people assume upon seeing such a message could be far worse than the original reason the person requested that the result be removed in the first place.
Is There Hope?
Google, the innovation giant, the legendary corporation scores of people turn to on a daily basis, has infinitely helped make data on the worldwide Web accessible to many. However, it has simultaneously brought about new and previously unknown problems it's unclear how to tackle. The unfortunate result is a sense of helplessness, not being able to control where private information ends up or how it's used, nor their site's visibility and financial income.
In light of these repeated breeches in trust, unfair competition and the apparent disregard for user experience, it's high time to seriously reconsider the depth of this dependency on one service. After weighing the consequences of continuously (and sometimes unknowingly) giving one corporation nearly unlimited access to users' private data as well as disproportionate control over their financial destiny, perhaps there's room to consider, individually, which measures can be taken to feel protected.