JavaScript SEO for Non-Developers


Today's SEO professional is required to have more technical knowledge than ever before. Nowhere is that more evident than when it comes to optimizing pages built primarily with JavaScript.
SEOs need to understand the difference between server-side (back-end) and client-side (front-end) rendering. They also need to be able to recognize sites built with JavaScript technologies like Angular.js, React.js and Backbone.js. Finally, SEOs need to understand the basic concepts of JavaScript SEO enough to provide best practice advice to developers and to determine if their recommendations were implemented properly. By the end of this article, you should be well on your way to reaching these goals.
Since 2013, developers have been incorporating JavaScript technology into Web development projects at a rapidly increasing pace, making JavaScript SEO more important than ever:
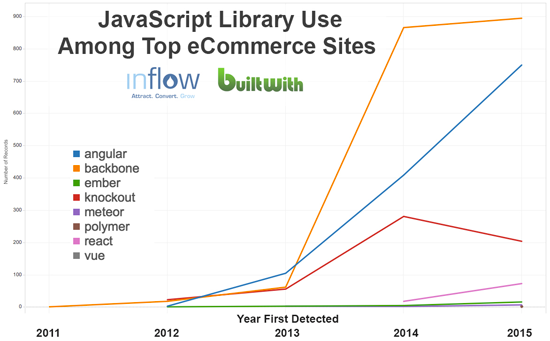
Identifying Websites Built on a JavaScript Framework
These types of JavaScript libraries and frameworks are used to develop advanced website interfaces, including single-page Web apps, which require certain SEO measures in order to be crawled correctly.
You might need to know JavaScript SEO if...
- You've seen a content-rich page with only a few lines of code (and no iframes) when viewing the source within the last few years.
- You see, or what looks like server-side code in the meta tags instead of the actual content of the tag. For example:

- You're asked to optimize a site with #! (hashbangs) in the URLs. For example:
www.example.com/page#!key=value
Crawling Websites Built With JavaScript
If the website uses hashbangs in the URL, you can crawl the site to get the "URLs" but not the content. To get the content, you'll need to replace the hashbang with the escaped fragment parameter using Excel, and import that new list of URLs for a new crawl. The Screamingfrog SEO crawling tool has a nice feature in the AJAX tab that will fetch the HTML snapshot of the content if you follow these guidelines. You can also do it with Deep Crawl. More on hashbangs and escaped fragments later.
If URLs are handled differently you may be able to crawl the site as normal. One of these days (hopefully soon) all professional crawler tools will incorporate a headless browser and give SEOs the option to have it render JavaScript.
Newsflash: Google Still Kind of Sucks At Handling JavaScript
Google would have developers think JavaScript is not something they need to be concerned about because everything is taken care of on Google's end. This is simply not true.
Any SEO who has dealt with a migration to a new site using JavaScript to handle ecommerce category page content can tell you that rankings will plummet - no matter what Google says on its blog - if certain precautions are not taken.
Less than two weeks after Google announced they can crawl JavaScript and that developers should no longer pre-render snapshots to show them, Google's own John Mueller admitted at the end of a Webmaster Central Hangout that they still had problems crawling Angular.js, and that the best solution (for now) is to pre-render the content for Googlebot.
SEO Problems with JavaScript
Although Google does execute JavaScript when crawling the Web, using client-side scripting to render content is currently fraught with problems like these.
#1 Just because a snippet of JavaScript can take the user to a different page does not mean it's the same as an HTML "href" link in terms of passing pagerank. This could explain why some sites lose rankings even when using best practices for JavaScript SEO.
window.location.href = "www.mysite.com/page2.php";
[Example of a JavaScript link that may not pass pagerank]
#2 According to a study from Builtvisible, Google may stop rendering the content if it takes more than about four seconds to load, leaving the page only partially indexed and cached.
#3 The same study shows that content requiring an "event" may not load at all. Examples include content that gets loaded after clicking a "more" button, image carousels or "tabs" to show further details about a product.
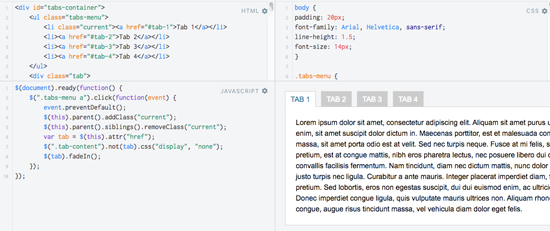
According to the Builtvisible study, content rendered this way may not get indexed.
#4 Some older technologies don't allow for universal JavaScript, where content can be rendered both on server as well as in the user's browser. Developers may need to configure a server that uses Phantom.js to render the page as HTML, to be used in conjunction with a pre-rendering middleware service like Prerender.io and Brombone to serve static snapshots of each page to users without JavaScript enabled, as well as search engines.
#5 Blocked resources can be a big problem with JS-heavy sites. Do not block JavaScript resources in the robots.txt file. If any of the JavaScript needed to fully render the page is located in a directory that Google cannot access, it will not be rendered by Google and the page will not be indexed and cached with that content.
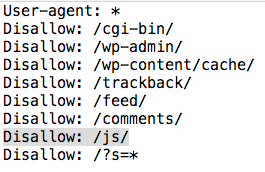
It is very important that Googlebot is not blocked from executing JavaScript required to render content on the page.
SEOs have to deal with misinformation from Google about the risk of "cloaking" when it comes to serving a pre-rendered snapshot of the page. It comes from this Google Webmaster Central post in which a Googler answers an important question:
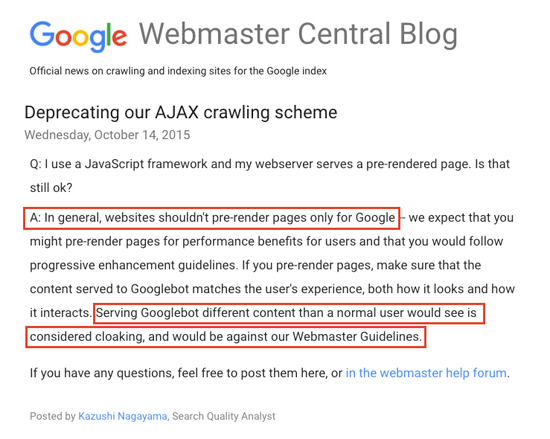
The highlighted portions are quoted by developers when pushing back on serving pre-rendered content to Googlebot.
But, as John Mueller told webmasters two weeks after this post was published, sometimes you have to pre-render content in order for Google to see it.
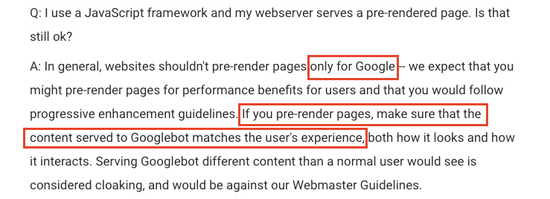
This is what SEOs and developers should be paying attention to. Don't single out Google. Show them the same snapshot you show others without JavaScript enabled.
If you show Googlebot the same content you're showing users without JavaScript enabled, and that experience is pretty much the same as what one would see with JavaScript enabled, you're not doing anything wrong and are very unlikely to be "penalized" for cloaking.
What's The Difference Between Server-Side and Client-Side Rendering?
Server-side rendering happens before the page is even loaded into the browser. Client-side rendering typically occurs in your browser. Search engines incorporate "headless browsers" into the crawling routine so they can "see" the page once all of the client-side content has been rendered - otherwise they'd miss out on all of the content that gets rendered client-side.
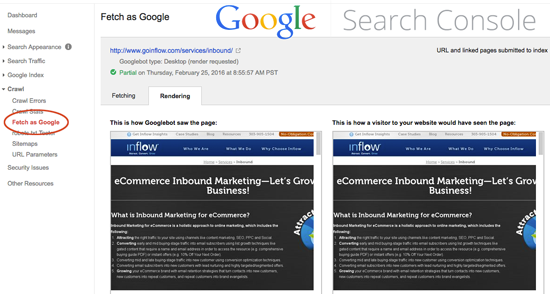
Basically, you want both of these windows to look the same. Googlebot uses a headless browser to render the page.
But there is another important issue other than the rendering of content - one that is even more confusing than trying to understand Google's conflicting and misleading advice about pre-rendering. Every "page" needs its own URL.
That's where escaped fragments and hashbangs have come from: New JavaScript technology adapting itself to old search engine technology. The important thing to note here is that neither is still being recommended as an optimal way to produce a unique URL for each page.
What Are Hashbangs and Escaped Fragments All About?
When developers first started using AJAX heavily, the URLs were constructed like this:
www.domain.com/#page. Internal anchor links like this are used to skip down the same page, rather than signifying a separate URL to be indexed.
Enter the "hashbang" solution. Putting a ! in front of #, as in www.domain.com/#!page. This had two benefits. First, it is seen by search engines as a unique URL, as opposed to a jump-link to another part of the page. Second, it makes the full URL visible to the server, which allows developers to pre-render the static content server-side for search engines and users without JavaScript enabled.
Use of the #! URL format instructs the search engine crawler to request an "escaped fragment" version of the URL. The web server then returns the requested content in the form of an HTML snapshot, which is then processed by the search engine. For example:
Crawler sees https://www.example.com/page#!content=123
Crawler requests https://www.example.com/page?_escaped_fragment_=content=123
Server returns a static, crawlable "snapshot" of /page#!content=123
So are Hashbangs the Answer to JavaScript Framework SEO?
Answer: No. There are other ways to go about it with better results.
The first way is to have links to content in the HTML, and to pull the URL and route to a specific resource based on that. This method treats routing the same way you'd traditionally do it.
For an example of routing that way, take a look at Pete Wailes' project: https://wail.es/fly-me-to-the-moon/. This site uses basic routing in JS to serve different pages based on the URL. This means you get a page refresh when changing URLs, just like you'd have on a traditional website.
Another way is to load stuff via XML Http Request (XHR), and to update the URL via the HTML5 history API. The logic behind the scenes works the same way as above, but the URL updates happen with JS, rather than through actual page changes.
So What's the Bottom Line Best Practice Right Now?
All "pages" should be accessible on their own, indexable URL. For example: https://www.domain.com/page1.
All important content on the page should be in the complete and final HTML rendering. This can happen server-side, or a pre-rendered snapshot (cache) of the page can be served to visitors without JavaScript enabled, and to search engines (for now).
Incorporate graceful degradation or progressive enhancement concepts, as a backup plan. Include HTML-based navigation/pagination on the page, even if the user has JavaScript enabled. Trouble elements, like image carousels, pagination and tabbed content can also be put into a "NoScript" tag, if necessary.