Apache Spark Adoption Growing Among Big Data Developers


Apache Spark, an open-source cluster computing framework which is often used as an alternative to Hadoop's two-stage disk-based MapReduce approach, is gaining adoption among developers looking for faster processing speeds.
Typesafe just released a report analyzing adoption patterns around Spark reveals some interesting adoption patterns the big data framework:
+ 71 percent have at least evaluation or research experience with Spark; 35 percent are using or plan to adopt soon.
+ 78 percent indicate that the most desirable feature of Spark is its improved processing power over MapReduce; 66 percent mention the ability to process event streams (which MapReduce can't do).
"The need to process Big Data faster has largely fueled the intense developer interest in Spark," according to Dr. Dean Wampler, Big Data Architect at Typesafe. "Hadoop's historic focus on batch processing of data was well supported by MapReduce, but there is an appetite for more flexible developer tools to support the larger market of 'mid-size' datasets and use cases that call for real-time processing."
Even with the increasing interest in Spark among developers, survey respondents indicated that a lack of in-house experiene and immaturity of the framework may be preventing adoption for now. Count on that to change as Big Data becomes the rule not the exception.
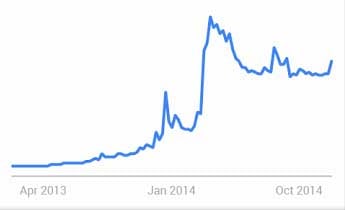
This Google Trends chart shows the rise in searches for "Apache Spark" over the past two years...