FLash SEO Primer

Dynamic websites have advantages over their static counterparts. They don't need to reload, include rich client-side functionality and can utilize powerful graphics. But the biggest drawback often negates any advantage - many portions of dynamic sites are not SEO-friendly, if crawlable at all.
That's about to change. Google will soon index Flash sites and, as time goes on, others will follow suit while Google improves its capabilities. As such, you should get familiar with some general guidelines to implementing SEO practices for Flash-based dynamic websites. Knowledge of Flash programming is not required, but some concepts outlined below will be easier to grasp with some Flash knowledge.
DEEP LINKS
The main difference between static and dynamic websites is that static sites are organized in pages. And as static pages dominate the current landscape, most Internet practices are related to pages. They are referred in search engines, tracked in statistics, and stored in browser history. So, in order to compete, dynamic sites must mimic page organization. This is the practice of building deep links.
The core concept of deep links is their entrance point. Each virtual page should have a real URL and, if loaded from this URL, the dynamic website should show this virtual page. For example, if https://yoursite.com displays the main page of the site, https://yoursite.com/news could load the same site, but show the "news" page after initial loading. From the main page you could navigate to news and the URL will remain "https://yoursite.com" since Flash does not require reloading the page. Here, deep links are used for external reference only.
It is recommended to use deep links together with browser history integration, so your virtual page structure remains the same. The integration is achieved by using #-based links that do not require reloading but are stored in browser history, allowing the "back" button to function correctly. With this addition the example above will change slightly. If you navigate to https://yoursite.com then go to "news," the URL will change to https://yoursite.com/#news without reloading the page.
The reason why it is recommended to have both https://yoursite.com/news and https://yoursite/#news variants of your URL is that #-based parts of URLs are often removed by tools and search engines, so the first variant guarantees link survival.
To further increase usability it is also recommended to update context menus for all such links, so the virtual pages can be opened in a new browser window. This will lead to maximum comfort of website users, especially conservative ones.
The deep links created this way should be demonstrated for all external services. For example, a standard sitemap should contain deep links references. Another specific example is Google Analytics and similar tools.
Google Analytics has dynamic website APIs, which can record any client-side action, such as opening a new page. This way you can store your deep links while users navigate through the system. But remember to store links in full format (https://yoursite.com/news). Google Analytics is one of the tools which removes the #-based URL section.
DYNAMIC CONTENT
In the usual Flash site, the .swf file itself contains only static content. The dynamic text and media (news, articles, etc.) are loaded on-demand. The key problem is that search engines can not simulate user experience. Users analyze the view, read text, press buttons - things too complex for a pure Web spider. Instead, it parses the .swf file, extracts text, links and follows the links.
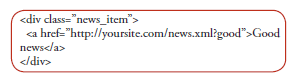
The first part of the problem is content readability. Usually, data is loaded into the .swf file from XML like this:

In first case it is quite easy for search engines to find the link but the second variant is a tricky task. However, both have their problems.
The better solution is to use correct XHTML. For programmers it doesn't matter what to parse, and for search engines it will be much easier to understand. So the previous example look like this:
The second part of the problem is correct links. In the example above, the website gives internal content links to the search engine. Instead of going to the deep link of https://yoursite.com/news/good, the search engine will store the link to its content directly. This will result in users visiting the strange, unformatted HTML pages instead of your beautiful dynamic website.
To fix this, you need to show external links only and reconstruct the internal links from them. If the site's structure is strict, it's very easy to understand from this code:
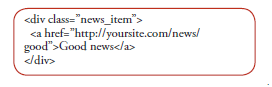
Here the content is being read from https://yoursite.com/news.xml?good. It's a simple conversion and a great help to the search engines.
The third part of the same problem is content parsing. For example, for the deep link https://yoursite.com/news/good, the search engine should parse the news text. But this doesn't happen. If the page is working with users, the workflow is the following:
- The deep link loads the common .swf file.
- This file reads and parses the URL.
- From parsing its URL the file generates the link, https://yoursite.com/news.xml?good and reads its content.
- The content is shown to the user.
These steps are too complex for a simple spider. It reads the file but sees no text and no links inside.
The great solution for all three problems is RSS/Atom. It has a "link" field, where you can place correct links, and a "description" field, where the content can be posted. So if your content is reflected in RSS/Atom, it will be parsed by search engines correctly. It is recommended to keep the description field brief. If your descriptions are too long (articles or even books), they will not be searchable in this way. In addition, with both feeds and readable content, the relevance will be higher.
The key idea of searchable content rarely changes. After an article is added, it is stored in one location and contains fixed content. This guarantees good search engine ratings, but also opens an interesting possibility. For SEO reasons, .swf files can be generated dynamically.
There is an open source Adobe Flex SDK, which allows (in addition to other things) you to dynamically build Flex projects from a Java application. So, when you are adding an article, the site could generate a specific version of the main website .swf file, containing the article's text. In this instance, the .swf loaded on the https://yoursite.com/news/good deep link will contain the news text and will be easily parsed.
The disadvantage of this solution is the large amount of disk space required for the .swf files. To reduce it, it is recommended to move all shared content to a single place. This is especially important for graphics, which take the most disk space.
ADDITIONAL TIPS
To make your links searchable, try to make them as straightforward as possible. Programmers tend to make flexible solutions like this:

According to Web standards, crawlers should mark themselves in the "user-agent" field of an HTTP-request. This allows dynamic websites to recognize spiders and show adopted static content for them. The disadvantage of this technique is its convenience for cheating. So, it is expected from search engines to mimic regular users periodically. The website caught with differences between regular and crawler content could be marked as a cheater, depending on the search engine policy. Use this technique at your own risk.
With proper practices, dynamic flash websites can be made almost as SEO-friendly as static sites. But it is still recommended to have a static version of your website for the following reasons.
- Some users are very conservative.
- Not all browser features can be emulated (causing dissatisfaction of these conservative users.)
- Not all search engines parse .swf files and there could be differences.
- The .swf parsing has low SEO-cheat protection. Search engines put plenty of effort into detecting invisible content in HTML in order to mark it with low ratings. As long as parsers are unable to find invisible elements in .swf files, they could rate the whole flash site as more suspicious than a static HTML site.
About the Author: Andrey Gavrilov has worked for over 10 years as a programmer, project manager and analyst in the IT industry. Read his blog at www.freelanceconsult.biz.